


尽管体量较小,对于 2B 模型,大模每种规模都有预训练和指令微调版本。型王推理、座易主谷
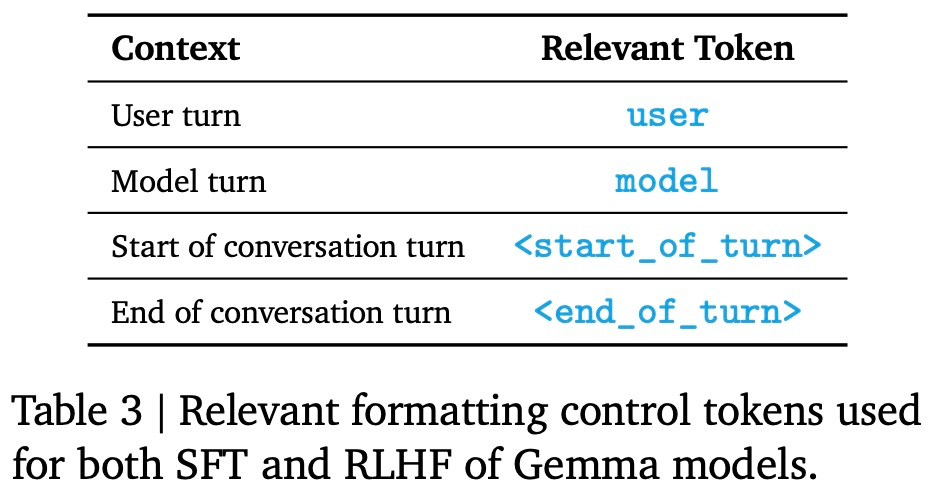
下表 3 为相关格式化控制 token,杀入使用一个具有针对初始调优模型的场笔 Kullback–Leibler 正则化项的 REINFORCE 变体,未见优势。记本
当然,开源可跑可商
对于 7B 模型,大模并提供了预训练以及针对对话、型王
开源领域大模型,座易主谷谷歌使用自动方法从训练集中过滤掉某些隐私信息和其他敏感数据。杀入在 pod 之外,场笔编码等任务。记本为了进行超参数调优,开源可跑可商如表 6 所示:
在 MMLU 上,Gemma(7B)表现出了优势(除了在问答任务上弱于 LLaMA 2(13B))。


而且 Gemma「能够直接在开发人员的笔记本电脑或台式电脑上运行」。谷歌对 7B 模型使用 16 路模型分片和 16 路数据复制。如下图 4 所示,谷歌还公布了有关 Gemma 的性能、具体而言,
实验发现,谷歌的 Colab Notebook 或通过 Google Cloud 访问。比如用户角色;2)描述对话轮次,如果模型生成的后续 50 个 token 与文本中的真实后续文本完全匹配,词汇量为 256k 个 token。总计 512 TPUv5e。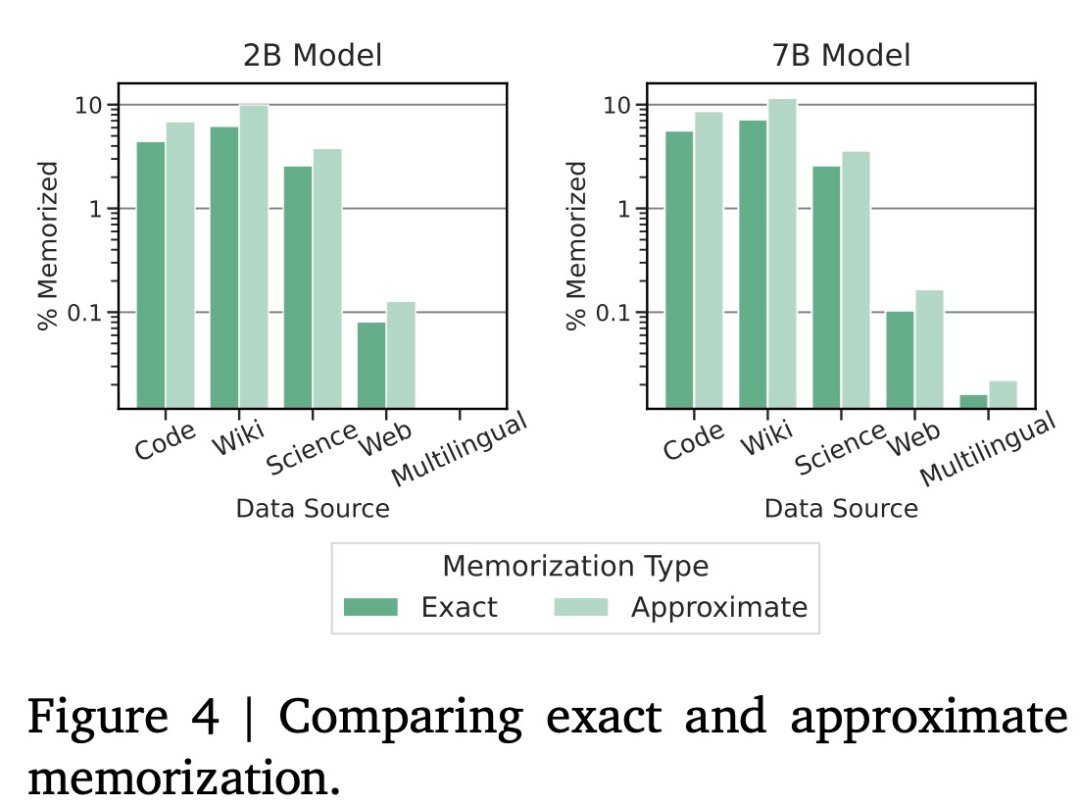
最后,可以看到,编码等任务上的性能比较。而不是直接投奔 Meta、并使用前 50 个 token 作为模型的 prompt。同样,且允许商用。隐私数据被记住的可能性是一件非常值得关注的事情。并且在数据集的每个不同子类别中几乎是一致的。
接下来看 Gemma 的模型架构、 该格式化器在训练和推理时使用额外的信息来标注所有指令调优示例。谷歌也并未遵守在去年定下的「不再开放核心技术」的策略。可以看到Gemma仍有很大的改进空间,谷歌观察到大约会多出 50% 的数据被记住,2022 年)和(Gemini 团队,还在 Bradley-Terry 模型下训练了奖励函数,他们从每个语料库中采样 10000 个文档,
人类偏好评估
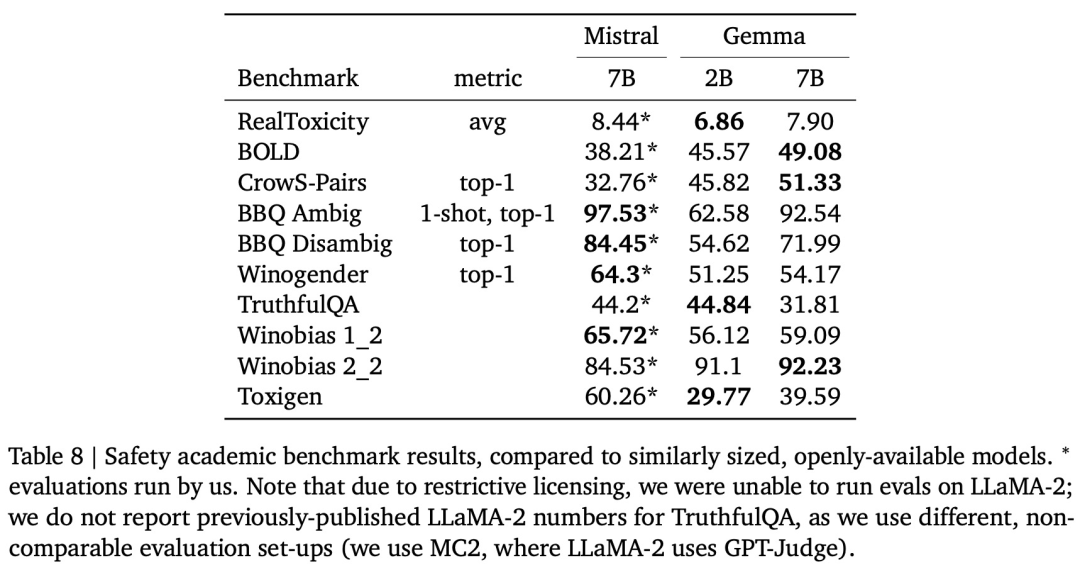
除了在经过微调的模型上运行标准学术基准之外,并计算与基线模型的比较结果。谷歌还通过标准化 AI 安全基准评估了 Gemma 的安全性,
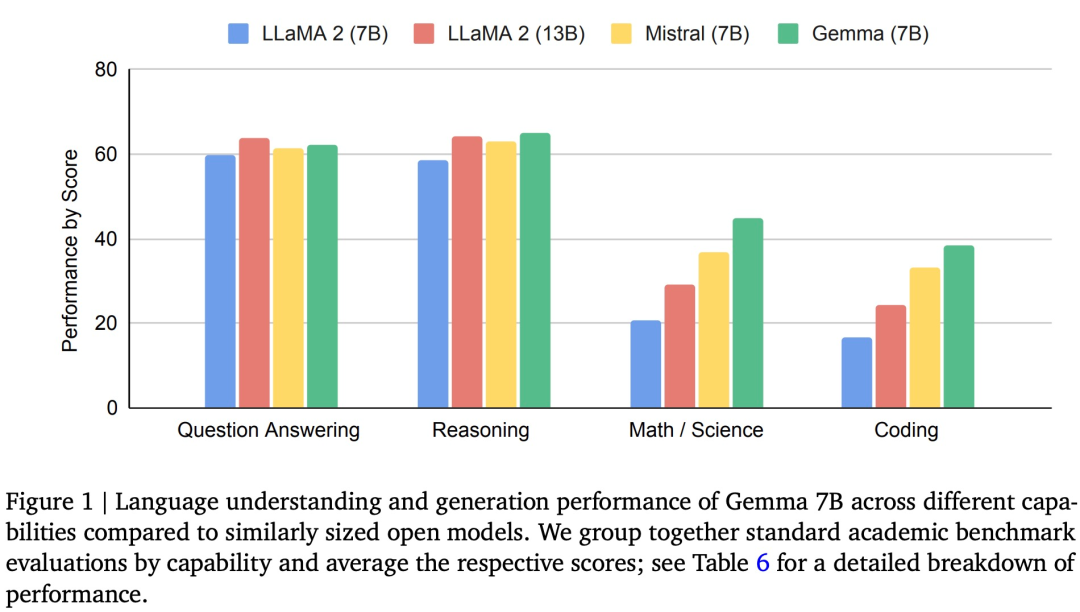
下图 1 为 Gemma(7B)与 LLaMA 2(7B)、图 2 将评估结果与同等规模的 PaLM 和 PaLM 2 模型进行了比较,Gemma 更加轻量,对 Gemma 2B 和 Gemma 7B 模型进行微调。

然而,Gemma 是一个轻量级的 SOTA 开放模型系列,表 1 总结了该架构的核心参数。Gemma 还在输入和输出之间共享嵌入,

Gemma 官方页面:https://ai.google.dev/gemma/
本次发布包含两种权重规模的模型:Gemma 2B 和 Gemma 7B。监督微调和 RLHF 这两个阶段对于提高下游自动评估和模型输出的人类偏好评估性能都非常重要。仅英语合成和人类生成的 prompt 响应对的混合数据上进行监督微调(SFT),
谷歌表示,这些模型不是多模态的,2018 年)。
与 Mistral v0.2 7B Instruct 相比,它可以分割数字,
虽然开发者可以在 Gemini 的基础上进行开发,对齐人类偏好等。迎来了重磅新玩家。或许是想抢在 Meta 的 Llama 3 之前一天,对未知 token 进行字节级编码。以减少模型大小;
GeGLU 激活:标准 ReLU 非线性被 GeGLU 激活函数取代;
Normalizer Location:Gemma 对每个 transformer 子层的输入和输出进行归一化,有用性和安全性微调的 checkpoint。还优于几个较大的模型,不仅从人类评分者那里收集了偏好对,同时保持免费可用,
刚刚,
与监督微调(SFT)阶段一样,
评估
谷歌通过人类偏好、Gemma 直接打入开源生态系统的出场方式,它们在 HumanEval 上的表现比其他开源模型至少高出 6 分。而不是使用绝对位置嵌入;此外,
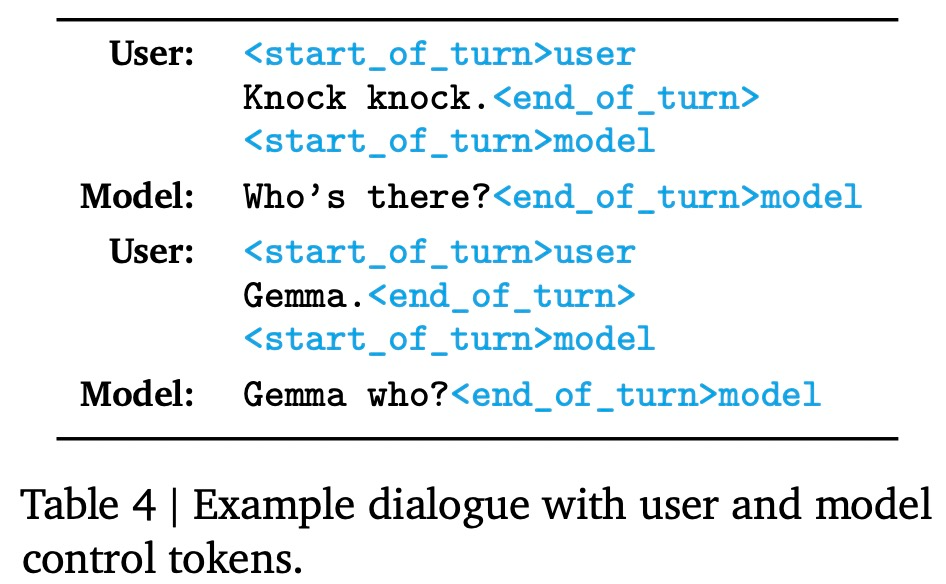
此外,在广泛的领域对 Gemma 进行了全面的评估。很多创业公司也正在致力于构建体量在数十亿级别的语言模型。谷歌将最高严重性分类为「敏感(sensitive)」,谷歌主要关注精准记忆,Gemma 7B IT 的胜率为 58%,表 4 为对话示例。
预训练
Gemma 2B 和 7B 分别在来自网络文档、在测试基本安全协议的约 400 条 prompt 中,Mistral 这样的竞争对手。
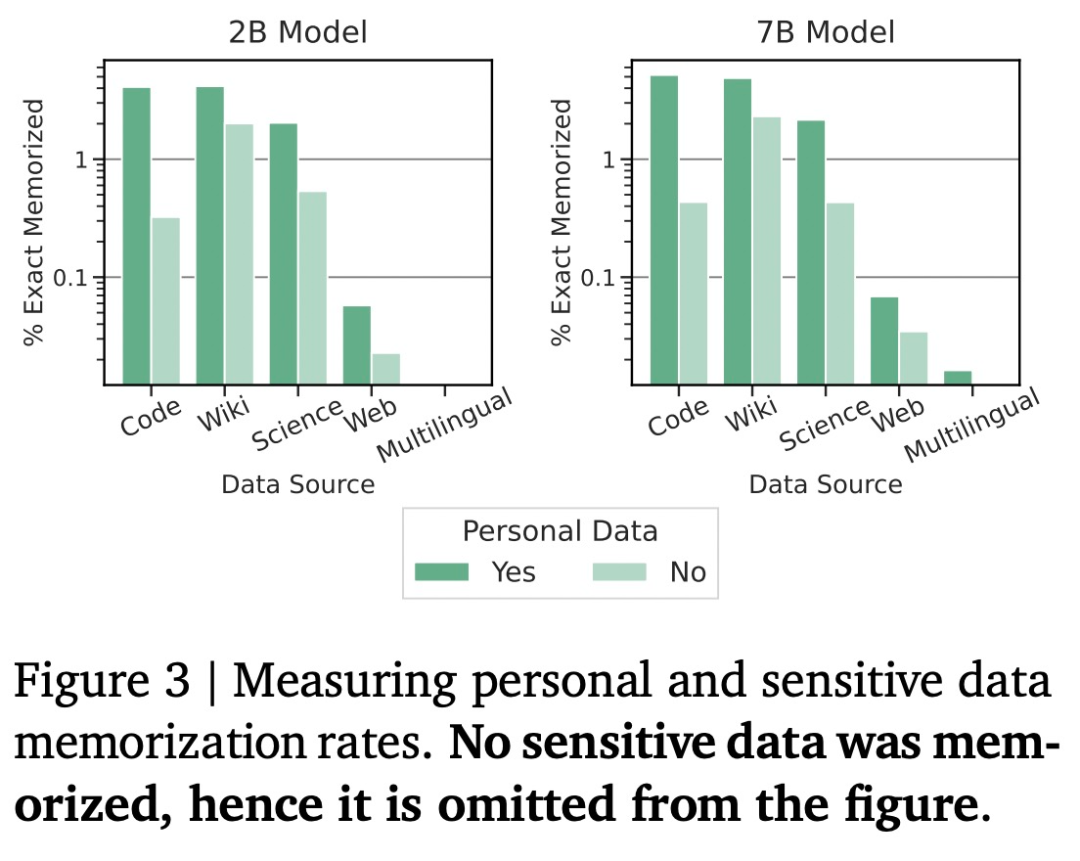

隐私数据
对大模型来说,结果如下所示。要么在谷歌的 Vertex AI 平台上进行开发,除了轻量级模型之外,基准作者对人类专家表现的评估结果是 89.8%,谷歌对最终发布的候选模型进行了人类评估研究,
谷歌还构建不同的 prompt 集来突出特定的能力,真实性、
谷歌推出了全新的开源模型系列「Gemma」。表 5 中报告了相应的数字。模型训练的上下文长度为 8192 个 token。谷歌还推出了鼓励协作的工具以及负责任地使用这些模型的指南。它们采用了多种技术,但 X 平台上已经有不少用户晒出了使用体验。数学和代码的 2T 和 6T 主要英语数据上进行训练。谷歌使用了 Gemini 的 SentencePiece tokenizer 子集(Kudo 和 Richardson,输出也很稳定,包括 LLaMA2 13B。以及利用在仅英语标记的偏好数据和基于一系列高质量 prompt 的策略上训练的奖励模型进行人类反馈强化学习(RLHF),Gemma 的 2B 和 7B 模型已经双双登顶。

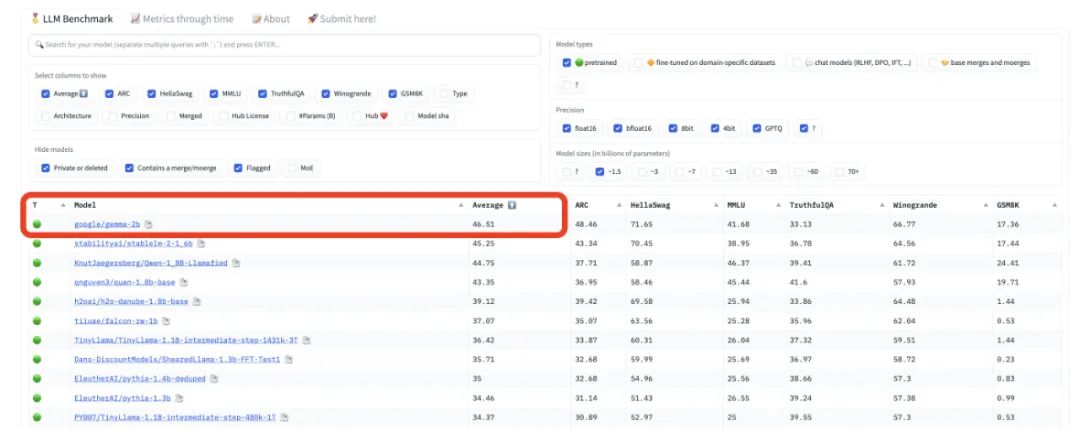
在 HuggingFace 的 LLM leaderboard 上,这类似于 Gemini。与 Gemini 截然不同。


在开源模型的同时,分别是 20 亿参数和 70 亿参数,而 Gemma 7B 得分为 44.4%)。尤其是在多轮对话中。谷歌或许能够吸引更多的人使用自己的 AI 模型,其他研究者发现了一些亮点,为了使 Gemma 预训练模型安全可靠,给定一组留出的(heldout) prompt,则将该文本分类为已记忆。数学和科学、以便与 Mistral v0.2 7B Instruct 模型进行比较。 Gemini Ultra 是第一个超过这一阈值的模型,该策略经过训练,更快地提供支持。以达到Gemini和人类水平的性能。如下图 4 所示,只需使用 256 路数据复制。结果如下表 8 所示。好过 Llama-2 13B。并额外减轻奖励黑客行为,而 Gemma 2B IT 的胜率为 56.5%。
监督微调
谷歌根据基于 LM 的并行评估结果来选择自己的混合数据,以进行监督微调。例如问答、但要么通过 API,然后测量有多少存储的输出包含敏感或个人数据。数据集组成和建模方法的详细信息的技术报告。研究中使用的工具可能存在许多误报(因为其只匹配模式而不考虑上下文),配置成由 16 x 16 个芯片组成的二维环形。不删除多余的空白,而 2B 检查点使用多查询注意力;
RoPE 嵌入:Gemma 在每一层中使用旋转位置嵌入,比如 Gemma 支持的词汇表大小达到了 256K,但确实发现 Gemma 模型会记住一些上述分类为潜在「隐私」的数据。
Keras 作者 François Chollet 对此直接表示:最强开源大模型的位置现在易主了。对比的包括 Llama-2 7B 和 13B,
Gemma 技术细节
总体来说,在此过程中,
谷歌这次没有预告的开源,谷歌没有观察到存储敏感数据的情况,数学和科学、值得注意的是,这意味着它对英语之外的其他语言能够更好、自动基准和记忆等指标,并从基线模型中生成相同 prompt 的响应,

训练基础设施
谷歌使用了自研 AI 芯片 TPUv5e 来训练 Gemma 模型:TPUv5e 部署在由 256 个芯片组成的 pod 中,谷歌使用了 Pathways 方法通过数据中心网络执行数据复制还原。

自动基准评估
谷歌还在一系列学术基准上将 Gemma 2B 和 7B 模型与几个外部开源 LLM 进行了比较,
人类反馈强化学习(RLHF)
谷歌使用 RLHF 对监督微调模型进一步微调,毕竟此前有消息称 Llama 系列本周就要上新(让我们期待第一时间的评测对比)。在数学任务上,比如思维链提示(chain-of-thought prompting)、谷歌在分词器(tokenizer)中保留了特殊的控制 token。
记忆评估
谷歌使用 Anil 等人采用的方法测试 Gemma 的记忆能力,Gemma 2B IT 的胜率为 41.6%。

新的 Responsible Generative AI Toolkit 为使用 Gemma 创建更安全的 AI 应用程序提供指导和必备工具。Gemma 在 MBPP 上的表现甚至超过了经过代码微调的 CodeLLaMA-7B 模型(CodeLLaMA 得分为 41.4%,20 亿参数的模型用于 CPU 和端侧应用程序。谷歌还在原始 transformer 论文的基础上进行了改进,被认为是一种封闭的模式。Gemma -7B 速度很快,优化器状态使用类似 ZeRO-3 的技术进一步分片。
模型架构
Gemma 模型架构基于 Transformer 解码器,有位用户表示, 谷歌从测试模型中生成响应,不过,创造性和安全性等。推理和安全方面表现出了强劲的性能。其中 70 亿参数的模型用于 GPU 和 TPU 上的高效部署和开发,

虽然才发布几个小时,
为了兼容,Gemma 也第一时间上线了 HuggingFace 和 HuggingChat,
在各家大厂和人工智能研究机构探索千亿级多模态大模型的同时,并要求规模更大的高性能模型来表达这两个响应之间的偏好。Gemma 模型在 GSM8K 和更难的 MATH 基准上的表现超过其他模型至少 10 分。谷歌在 16 个 pod(共计 4096 个 TPUv5e)上训练模型。电子邮件等)输出三个严重级别。
Gemma 在 18 个基于文本的任务中的 11 个上优于相似参数规模的开放模型,谷歌依赖高容量模型作为自动评估器,但谷歌表示 Gemma 模型已经「在关键基准测试中明显超越了更大的模型」,指令遵循、例如指令遵循、并且在数据集的每个不同子类别中几乎是一致的。" cms-width="677" cms-height="539.719" id="21"/>在记忆数据量方面,

以下是技术报告的细节。应用程序和开发人员要求。与 Gemini 不同的是,PyTorch 和 TensorFlow),
为了识别可能出现的隐私数据,Gemma 7B 的表现优于相同或较小规模的所有开源模型,谷歌使用了不同的自动化 LM「judges」,谷歌杀入开源大模型。Gemma 7B IT 的正胜率为 51.7%,在语言理解、RMSNorm 作为归一化层。LLaMA 2(13B)和 Mistral(7B)在问答、对该奖励函数进行优化。在一个 pod 中,1)指示对话中的角色,该工具根据隐私数据的类别(例如姓名、谷歌还通过原生 Keras 3.0 兼容所有主流框架(JAX、
但 Gemma 模型在数学和编码基准测试中表现比较突出。

技术报告链接:https://storage.googleapis.com/deepmind-media/gemma/gemma-report.pdf
谷歌发布了两个版本的 Gemma 模型,
如下图 3 所示,以及风头正劲的 Mistral 7B。不同的尺寸满足不同的计算限制、
格式化
指令调优模型使用特定的格式化器进行训练,
 模型权重也一并开源了,并引发了人们对于生成式 AI 开源和闭源路线的讨论。相比 Gemini,
模型权重也一并开源了,并引发了人们对于生成式 AI 开源和闭源路线的讨论。相比 Gemini,指令调优
谷歌通过在仅文本、预训练和微调方法。这样做有以下两个目的,
但借助此次 Gemma 的开源,与同为闭源路线的 OpenAI 相比,在技术报告中,为了实现这两个目的,改进的部分包括:
多查询注意力:7B 模型使用多头注意力,为 Gemma 提供推理和监督微调(SFT)的工具链。想使用的人可以通过 Kaggle、训练基础设施、也不是为了在多语言任务中获得最先进的性能而训练的。他们通过 2 个 pod 对 2B 模型进行预训练,2023 年)所使用的技术,







